In the high-stakes environment of the operating room, a surgeon’s cognitive load is at its absolute limit. They are simultaneously managing physical instruments, monitoring patient vitals, and interpreting a 2D video feed of complex 3D anatomy.
As I’ve discussed throughout this series, we have built powerful tools to help. We have CNNs that can classify tissue (Part 6) and YOLO architectures that can track instruments at 60 FPS (Part 7).
However, even with these “Eyes,” the surgeon is still forced to do the heavy lifting of interpretation. The system says, “Here is an object,” but the surgeon has to ask, “What does that mean for my next incision?”
This gap is where errors occur. To truly “cut decision time,” as one of the reader noted in our community discussion, we need an AI that doesn’t just see—it understands and communicates.
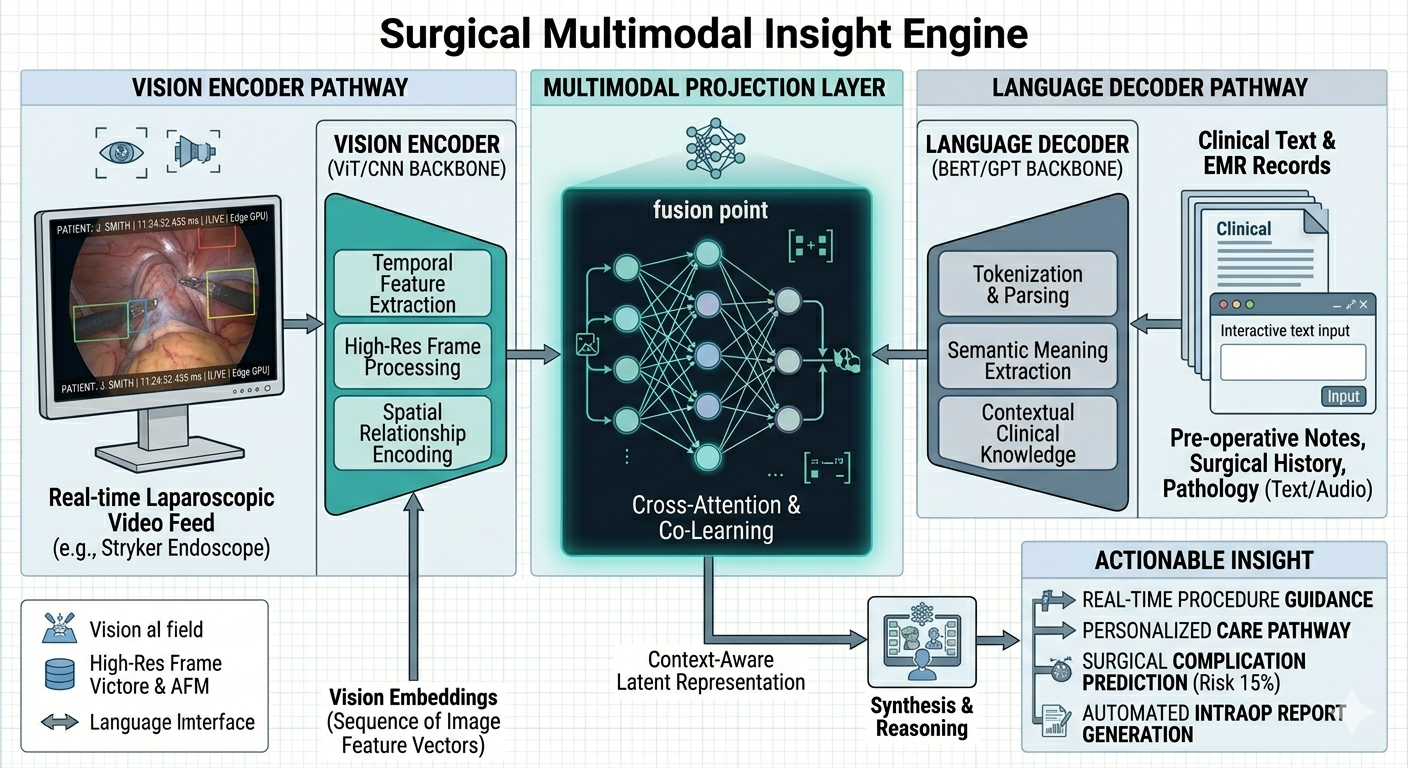
The VLM: A Unified Neural Architecture Traditional AI in MedTech is “unimodal.” You have one model for vision and a separate model for text. Bridging them requires complex, fragile “glue code” that often results in what some describes as “confident sounding guesswork” because the two models don’t share a common semantic understanding of the scene.
Vision-Language Models (VLMs) represent a fundamental architectural shift. Instead of two models, we build a single, multimodal transformer.
The Vision Encoder: Captures the spatial features of the surgical field (the “where”). The Language Decoder: Understands the clinical intent and medical terminology (the “what”). The Semantic Bridge: This is the secret sauce. We project the visual features into the same mathematical space as the language features.
The result? The AI “sees” the pixels of a hepatic artery and “understands” the word “artery” as the same mathematical concept. This allows for Visual Question Answering (VQA).
Case Study: From Detection to Dialogue Drawing on the learnings from my previous architectural work in surgical AR and industrial simulation, I am helping firms move beyond static overlays.
In a theoretical surgical VLM workflow, the interaction looks like this:
Surgeon: “System, check the distance from the current cautery tip to the ureter.” VLM Architecture: The vision encoder locates both items; the language decoder understands the spatial query; the multimodal layer calculates the Euclidean distance in the 3D projection. Result: The HUD instantly displays: “Distance: 4.5mm. Warning: Proximity threshold exceeded.”
This reduces the “search and interpret” time from seconds to milliseconds. In surgery, those seconds are the margin of safety.
Article content The Zero-Guesswork Mandate The biggest hurdle for VLMs in healthcare is grounding. We cannot allow an AI to “hallucinate” the position of a nerve.
Elite architectural design solves this by using Deterministic Guardrails. We don’t just ask a VLM to “guess” what it sees. We anchor the VLM’s visual encoder to a high-precision, low-latency “Ground Truth” engine—like the YOLOv8 instrument trackers we discussed in Part 7.
By using CV to “ground” the LLM, we ensure the output is based on physical reality, not probabilistic guesswork.