Prompt engineering has been branded as a “chatting” skill. In the MedTech sector, this is a dangerous misconception.
When you treat an LLM like a chatbot, you get chatbot-level reliability. When you treat an LLM as a programmable reasoning engine, you get clinical-grade output. In my experience architecting solutions across both my startup career and recent collaborations, I have found that standard, unstructured prompting is the primary point of failure for healthcare AI implementations.
The Failure of “Standard” Prompting
If you ask an LLM to “summarize this patient chart,” it will do exactly what it’s told: it will generate a summary based on whatever it thinks is important.
This is the failure point. The model does not know your clinical hierarchy, your department’s specific risk-scoring protocol, or the necessary audit trail required for compliance. Without explicit, structured constraints, you are relying on the model’s “best guess.”
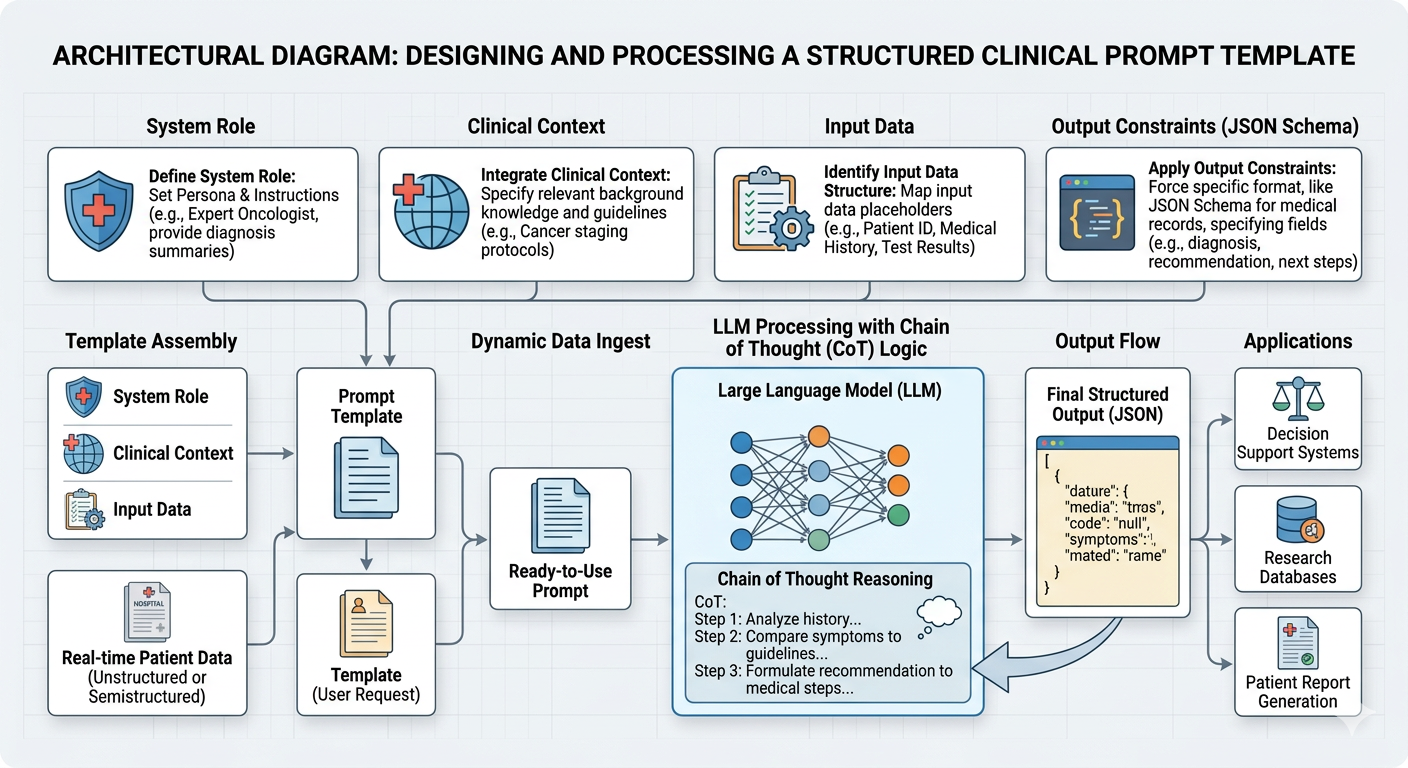
The Architectural Pivot: Precision Engineering
We must shift our mindset from “chatting” to Precision Engineering. This involves three architectural pillars:
System-Level Personas: We do not just ask the model to summarize. We define its clinical reality: “You are an assistant to a Senior Cardiologist. Your sole focus is the detection of anomalies in cardiac telemetry data. Ignore all conversational filler.” Constraint Enforcement: We treat the prompt as a schema contract. If the application requires the output to be JSON for downstream analysis, the prompt must explicitly dictate the schema, field types, and nesting. If the model deviates, the application fails. Chain-of-Thought Guardrails: We force the model to document its clinical logic before it generates the final recommendation. “Before providing the summary, list the key diagnostic criteria identified in the clinical notes and explain their weightage.” This provides the audit trail necessary for clinical review.
My Approach: During my time at IIT Bombay, I was trained to view systems as sets of mathematical constraints. In the startup world, I learned that these constraints must be performant and scalable. When we combine these, we create prompt templates that are not just instructions—they are functional requirements for the AI’s reasoning process.
Conclusion: Precision is the difference between a tool that assists a surgeon and one that causes errors. If you are a MedTech leader looking to architect clinical-grade AI that prioritizes safety and regulatory compliance over generic performance, let’s talk. Send me a DM to schedule a strategic consultation.