In the pharmaceutical and clinical research industries, speed is everything. A delay of just a few months in a clinical trial can cost upwards of $20-50 million in lost market potential. This is why the industry is rushing to adopt Generative AI to automate the synthesis of trial protocols and regulatory submissions.
But there is a catch. In clinical trials, an error—or a “hallucination”—in an AI-generated summary isn’t just a technical glitch; it is a regulatory blockade that can derail years of investment.
The “Hallucination” Crisis
LLMs are probabilistic. They are designed to predict the next token, not to guarantee factual accuracy. When a VP of Innovation asks an LLM for a summary of a 500-page clinical trial protocol, they aren’t just looking for “general knowledge.” They need a distillation of the specific, documented data.
If an LLM pulls an incorrect drug dosage or trial inclusion criterion out of thin air, that mistake enters your regulatory documentation. This is the precise reason why the industry remains hesitant to automate the “last mile” of clinical research.
The Architectural Solution: Grounding via RAG
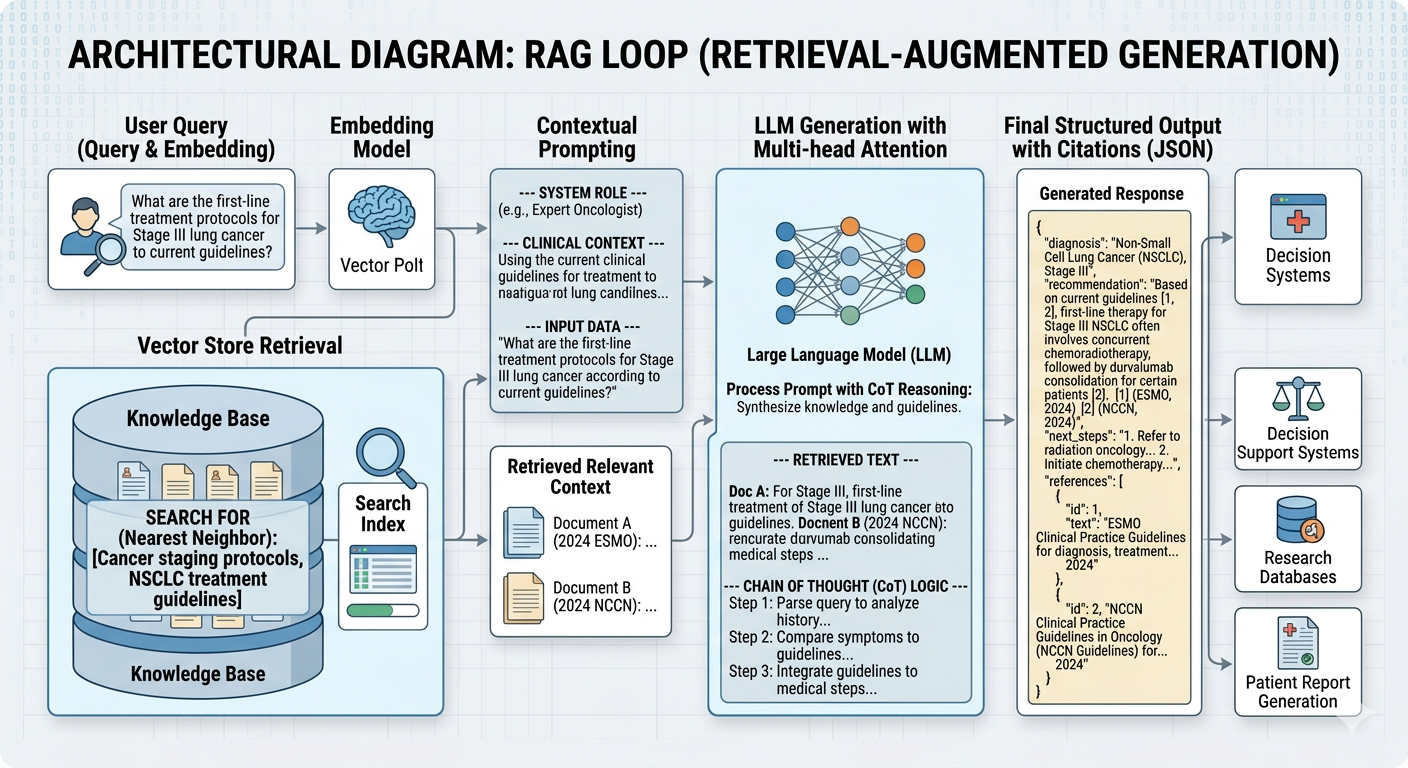
The answer is Retrieval-Augmented Generation (RAG). RAG is not an “add-on.” It is a fundamental shift in how we architect AI. Instead of expecting the model to hold all clinical knowledge in its memory, RAG provides the model with a “dynamic textbook.” The system follows three architectural phases:
The Embedding Pipeline (The Knowledge Librarian): We preprocess our clinical trials, PDF protocols, and regulatory documents, converting them into vector embeddings. This is the foundation of our library. The Semantic Retrieval Layer (The Search Engine): When a user asks, “What were the primary side effects in Cohort B?”, the system performs a vector search. It doesn’t ask the LLM; it queries the vector database to retrieve the specific text segments from the trial document that discuss Cohort B. The Grounded Generation Layer (The Synthesis): We feed only the retrieved text segments to the LLM along with the user’s question. We force the model into a constrained instruction: “Answer using only the provided context. If the answer is not in the context, say ‘I don’t know.’”
Business Impact & ROI
In my work on a recent project, we architected a RAG pipeline to automate regulatory compliance reporting.
The result? We reduced the time required for senior clinical researchers to compile a baseline report from three days to approximately four hours. That is an 80% increase in operational efficiency for the most expensive researchers in the company. Beyond just the hourly rate of researchers, consider the risk mitigation. By grounding the AI in the original clinical documents, we achieved a “zero-hallucination” output for verified sections, creating an automated audit trail where every statement in the generated document could be linked back to a specific page and paragraph in the trial documentation.
Bridging Theory and Practice
At IIT Bombay, I studied the principles of information retrieval and information theory. In my years within the startup ecosystem, I learned that the theory fails if it cannot handle the scale of a production environment.
When you build a RAG pipeline for healthcare, you are building a Clinical Knowledge Management System. It needs to be:
Secure: Embedding data must stay within the clinical VPC. Traceable: The architecture must return source citations (Page X, Paragraph Y). Scalable: The vector storage layer (like Chroma or Milvus) must handle millions of documents without latency spikes.