This is Part 1 of my 12-part series on Architecting AI in Healthcare.
Modern healthcare is in the midst of a data crisis.
We generate massive amounts of patient information every day—electronic health records (EHR), physician dictations, clinical trial reports, and multi-modal diagnostic data. Yet, as a consultant in this space, I consistently see the same pattern: organizations are spending millions to store this data, yet they struggle to derive actionable insights that reduce surgical errors, speed up diagnostic times, or optimize treatment paths.
This is the Unstructured Data Trap.
Why Standard AI Fails in the Clinical Environment
The common mistake is treating healthcare AI like a standard software problem. CTOs and Innovation VPs often deploy generic LLMs, expecting them to “understand” clinical notes.
They don’t.
Generic models are trained on general internet text. They lack the clinical nuance required to understand the difference between an allergy note and a primary diagnosis. Worse, they lack the architectural safeguards required for HIPAA compliance and data sovereignty. When these models fail, they don’t just provide bad advice—they hallucinate clinical facts.
The Architectural Solution: From Text to Meaning
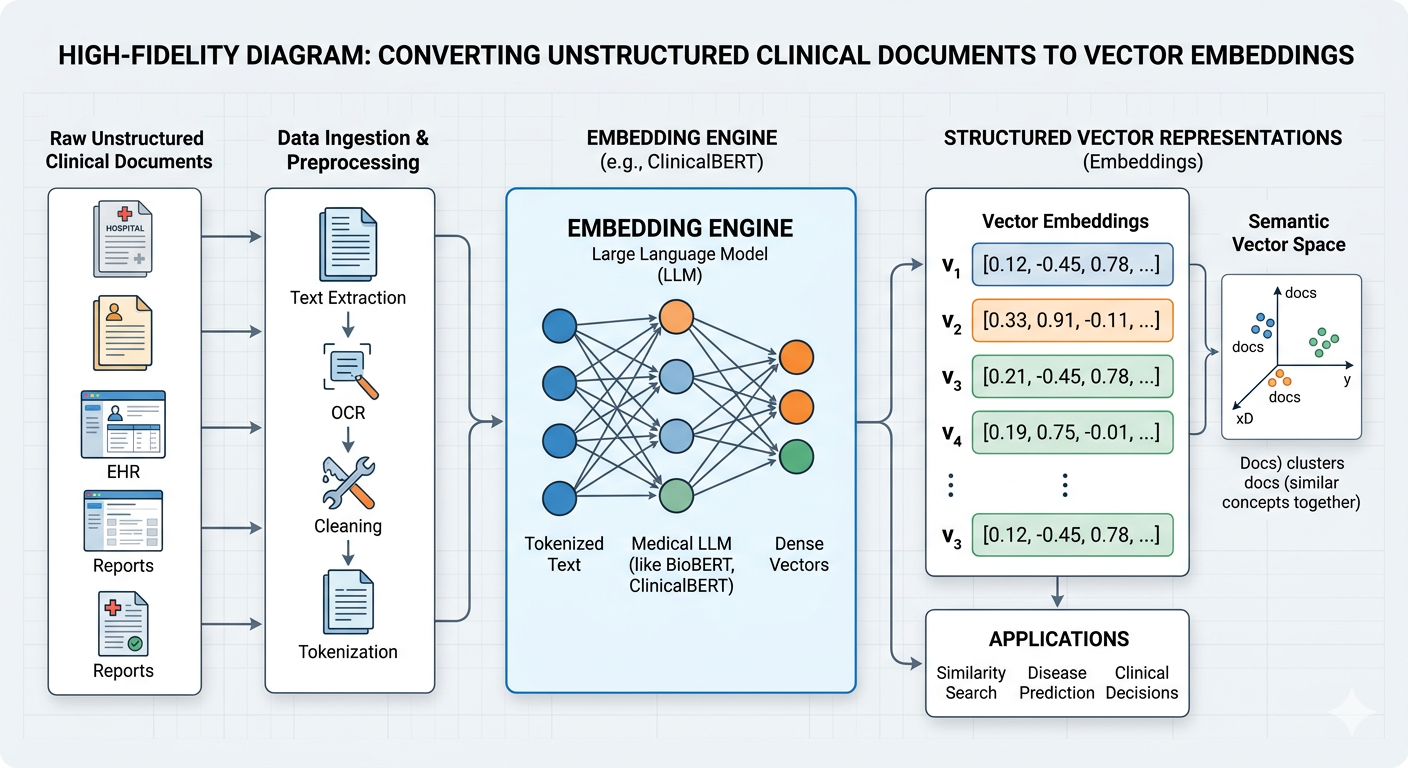
To move from “drowning in data” to “insight,” we must fundamentally change our architectural approach. We begin at the level of the individual token.
During my foundational work at IIT Bombay, I first explored the math behind representation. Later, during my 8-9 years building agile AI startups, I learned that the most critical architectural decision is how you translate unstructured medical text into a high-dimensional mathematical space.
This is where LLM Embeddings come in.
Unlike one-hot encoding, which treats every word as an isolated island, embedding models (like those from the transformers library) project clinical language into a dense vector space. In this space, aspirin and anticoagulant are positioned close together. Lisinopril and hypertension have a contextual proximity that the model understands before it ever sees a query.
The Architectural Insight: By embedding clinical documents into a structured vector space, we are not just digitizing text; we are creating a semantic index. This index acts as the ground truth for every future application we build, from automated triage assistants to clinical trial synthesis bots.
If your AI architecture isn’t built on a foundation of semantically accurate, secure, and domain-specific embeddings, your entire downstream AI strategy is built on sand.
Conclusion: The path to clinical AI maturity is not found in the latest flashy model; it is found in the architectural discipline of how we structure our data. If your organization is ready to move beyond the prototype phase and architect high-impact AI systems for the operating room or the research lab, send me a DM. Let’s schedule a strategic consultation to discuss your specific infrastructure requirements.